Java 知识 -- volatile
本文最后更新于:5 天前
⚡特性
volatile 关键字可以实现并发编程中的有序性和可见性,但是无法保证原子性
volatile 关键字首先具有"易变性",声明为 volatile 变量编译器会强制要求读内存,相关语句不会直接使用上一条语句对应的的寄存器内容,而是重新从内存中读取。
其次具有"不可优化性",volatile 告诉编译器,不要对这个变量进行各种激进的优化,甚至将变量直接消除,保证代码中的指令一定会被执行。
最后具有"顺序性",能够保证 volatile 变量间的顺序性,编译器不会进行乱序优化。不过要注意与非 volatile 变量之间的操作,还是可能被编译器重排序的。
需要注意的是其含义跟原子操作无关,比如:volatile int a; a++; 其中 a++ 操作实际对应三条汇编指令实现”读-改-写“操作(RMW),并非原子的。
volatile 的读性能消耗与普通变量几乎相同,但是写操作稍慢,是因为它需要在写入之后加入的 StoreLoad 这个内存屏障的性能开销特别大。
⚡使用场景
-
DCL单例
-
标志位
-
并发集合 ConcurrentHashMap 中 table 数组和 Node 节点中的 val 和 next 数据成员
⚡实现原理
Java 语言中 volatile 变量可以被看作是一种轻量级的同步,因为其还附带了 acquire 和 release 语义。实际上也是从 JDK5 以后才通过这个措施进行完善,其 volatile 变量具有 synchronized 的可见性特性,但是不具备原子特性。
在 Java 程序运行的时候,即 JVM 执行 volatile 变量的时候动态的处理:
-
在每个volatile写操作的前面插入一个StoreStore屏障。
-
在每个volatile写操作的后面插入一个StoreLoad屏障。
-
在每个volatile读操作的后面插入一个LoadLoad屏障。
-
在每个volatile读操作的后面插入一个LoadStore屏障。

⚡内存屏障又是在哪里加入进来的呢?
JVM 级别或者说是编译器级别的内存屏障
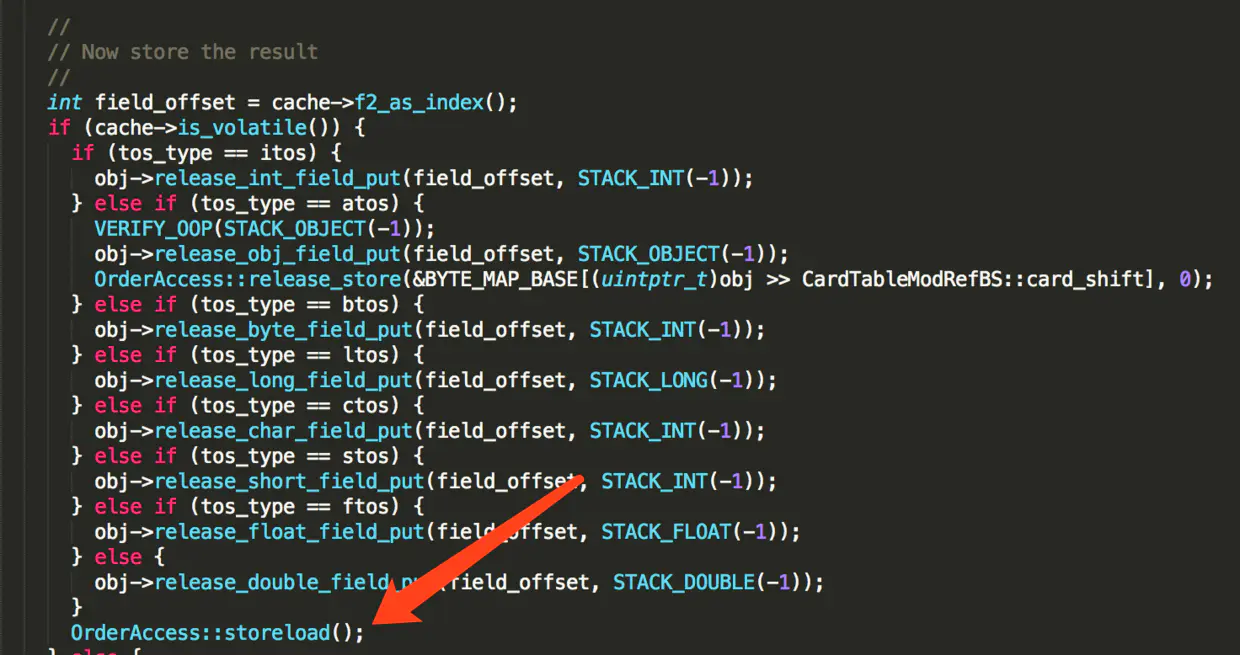
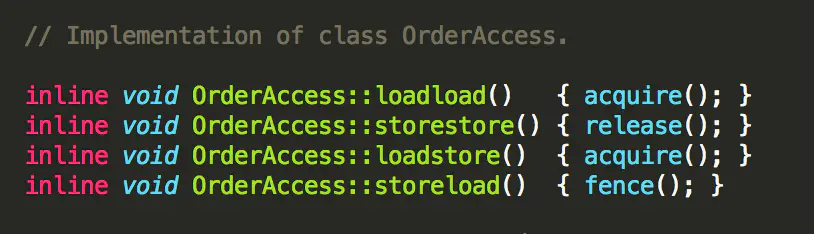

CPU 提供了三种内存屏障系统原语:
-
sfence
-
mfence
-
lfence
实际上 volatile 底层没有使用 CPU 的原语,原因是:不是大多数 CPU 都支持的上面的系统指令
volatile 关键字写入的时候才使用 Lock 指令的原因是:大多数 CPU 都支持
同理,volatile 关键字在读取的时候没有直接使用 CPU 的原语的原因也是可能会跨平台而不支持的问题,所以在 C++ 层面处理
-
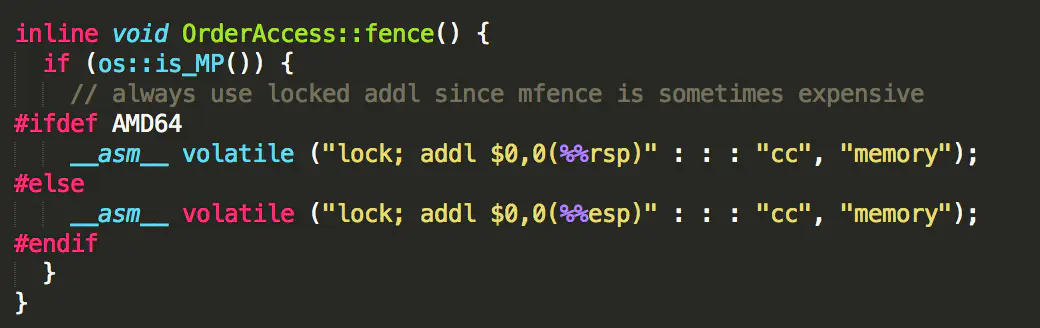
首先这是在写入 volatile 变量之后才会加入 lock指令
Java 语言中由 volatile 修饰的变量,赋值后多执行了一个"load addl $0x0, (%esp)" 操作,这个操作相当于一个 lock 指令
根据 Intel x64 CPU 官方文档:
Intel® 64 and IA-32 Architectures Software Developer’s Manual
8.1.2.2 Software Controlled Bus Locking
For the P6 family processors, locked operations serialize all outstanding load and store operations (that is, wait for them to complete). This rule is also true for the Pentium 4 and Intel Xeon processors, with one exception. Load operations that reference weakly ordered memory types (such as the WC memory type) may not be serialized.
其中
locked operations serialize all outstanding load and store operations
说明其实LOCK指令前缀包含了MFENCE的效果,而MFENCE保证插入StoreLoad
而具体的内存屏障的种类由执行这段程序的 CPU 硬件决定
Lock 指令有两种实现方式:
-
如果是现代 CPU 并且数据已经被CPU缓存了,并且是要写回到主存的,则可以用cache locking处理问题。
Intel使用"Cache Locking"机制,其实质是 Ringbus + MESI协议。
其步骤是:若干个CPU核心通过ringbus连到一起。每个核心都维护自己的Cache的状态。如果对于同一份内存数据在多个核里都有 cache,则状态都为S(shared)。一旦有一核心改了这个数据(状态变成了M),其他核心就能瞬间通过ringbus感知到 这个修改,从而把自己的cache状态变成I(Invalid),并且从标记为M的cache中读过来。同时,这个数据会被原子的写回到主存。最终,cache的状态又会变为S。
这相当于给cache本身单独做了一套总线(要不怎么叫ring bus),避免了真的锁总线。
-
第一种条件不满足,那么还是得锁总线。
因此,lock到底用锁总线,还是用cache locking,完全是看当时的情况。当然能用后者的就肯定用后者。
-
-
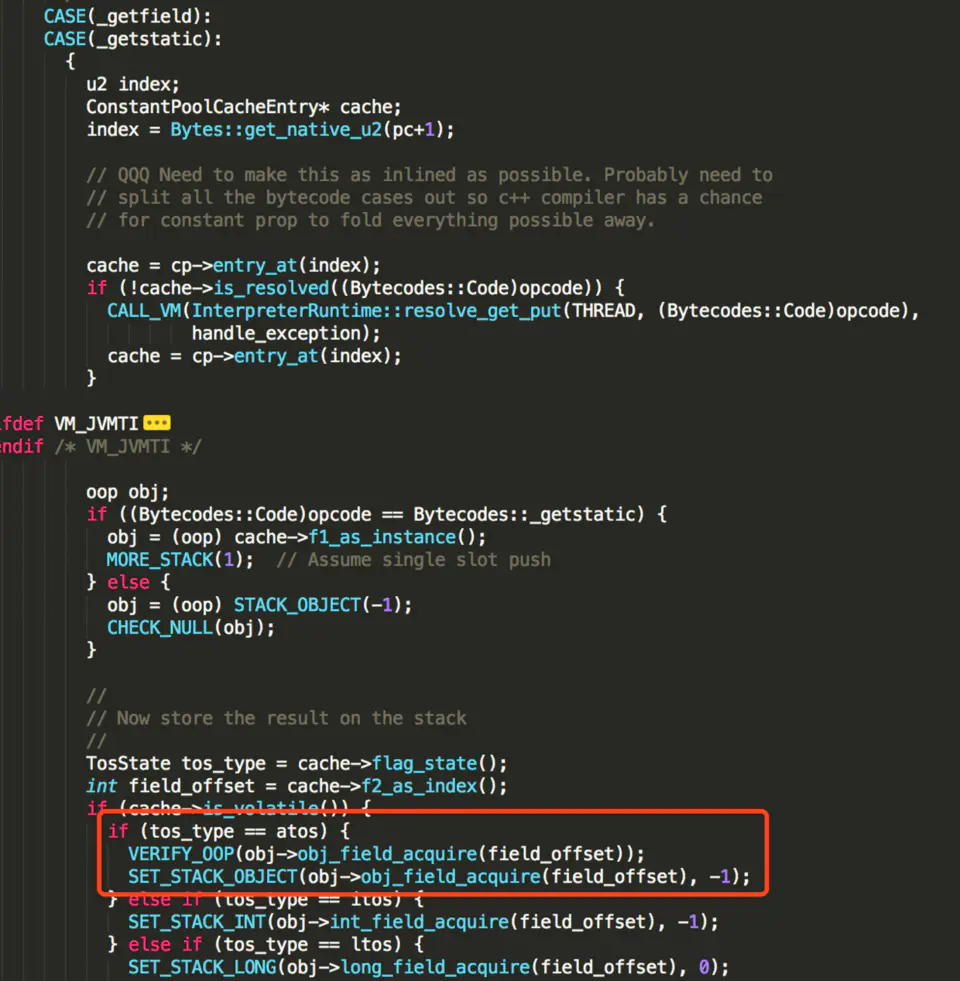
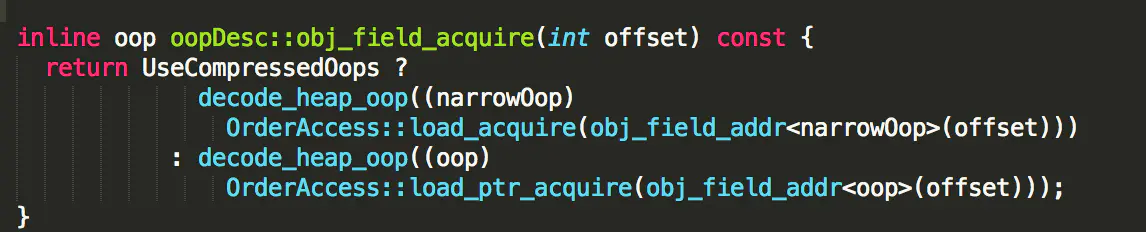
对于 volatile 读来说
而 obj->obj_field_acquire(field_offset) 放法实际上就是:
inline jint OrderAccess::load_acquire(volatile jint* p) { return *p; }读取实际上是基于 C++ 的 volatile 实现
⚡volatile 使用条件
Java实践中仅满足下面这些条件才应该使用volatile关键字:
-
变量写入操作不依赖变量当前值,或确保只有一个线程更新变量的值
-
该变量不会与其他变量一起纳入
-
变量并未被锁保护
⚡注意
-
错误:volatile 读取之前在读取之前加入读屏障刷新到主存,volatile 写之后加入写屏障刷入到主存
首先,这里加入内存屏障的位置其实恰好相反,写入是在写入之前加入屏障禁止指令重排,读取也是在读取之后加入内存屏障来禁止指令重排
其次,从缓存刷入到主存并不是由内存屏障去处理的,这是通过 MESI 协议决定的,内存屏障仅仅只是决定 Store Buffer 刷入 Cache Line
这个其实很好理解,CPU 使用数据是必须是在 Cache Line 或者寄存器里面,那直接刷入内存其实没有意义,因为要读取的时候还是需要从内存当中去读数据到 Cache Line,而真正的刷入主存的意思应该是刷入到 JMM 意义上的主存(即 CPU 的 Cache Line 或者寄存器),这样才能保证变量的可见性
-
对于 volatile 变量的读写,在字节码其实并不能体现出来,只是在字节码标记 volatile 变量,而真正起作用是在字节码转化为汇编指令的时候根据 CPU 的特性来加入内存屏障
-
volatile 读取的免费的吗?
不是。因为它会禁止指令重排,以及禁止其它的各种的优化
本博客所有文章除特别声明外,均采用 知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议 。转载请注明出处!