JVM 知识 -- 对象的 hashcode
本文最后更新于:4 天前
⚡方法流程
hashCode 有时会被误认为返回的就是对象的存储地址,事实上这种看法是不全面的,确实有些JVM在实现时是直接返回对象的存储地址,但是大多时候并不是这样,只能说可能存储地址有一定关联。
java.lang.Object#hashCode()方法是 native 方法,最终会调用 ObjectSynchronizer::FastHashCode 方法获取hashcode,Hot Spot 虚拟机执行流程如下:
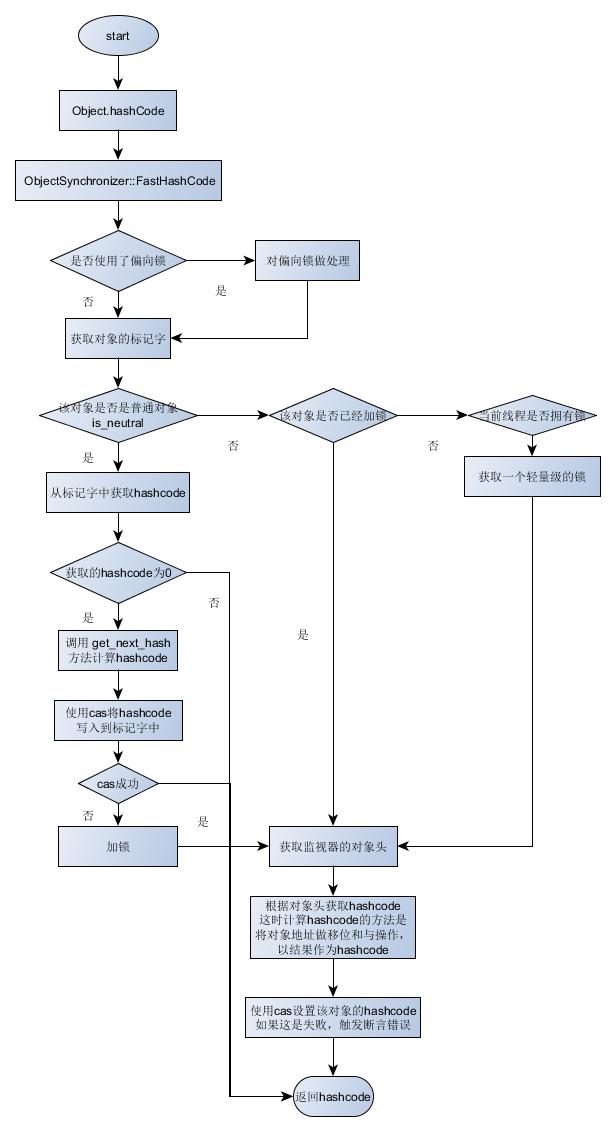
具体到计算hashcode时,会涉及到 get_next_hash 方法(在 synchronizer.cpp 中,用于计算新的 hashcode)和 hash 方法(在 markOop.hpp 中,用于获取已有的 hashcode)
其中,hash 方法的实现是先获取该对象的标记字对象,然后对该标记字对象的的地址做位移和逻辑与操作,以结果作为hashcode
而 get_next_hash 方法会根据传给 JVM 的参数 -XX:hashCode=n 来选择使用哪种方法生成对象的hashcode:
- hashCode=0,使用系统生成的随机数作为hashcode
- hashCode=1,对对象地址做移位和逻辑操作,生成 hashcode
- hashCode=2,所有的hashcode都等于1
- hashCode=3,用一个自增序列给hashcode赋值
- hashCode=4,以对象地址作为hashcode
- hashCode=其他,复杂的位操作
所以,其实 hashCode() 方法和 JVM 具体实现甚至与用户的参数设置有关,除了和地址相关之外,还有使用随机数,自增序列的选择
hashcode 默认存储在对象的对象头
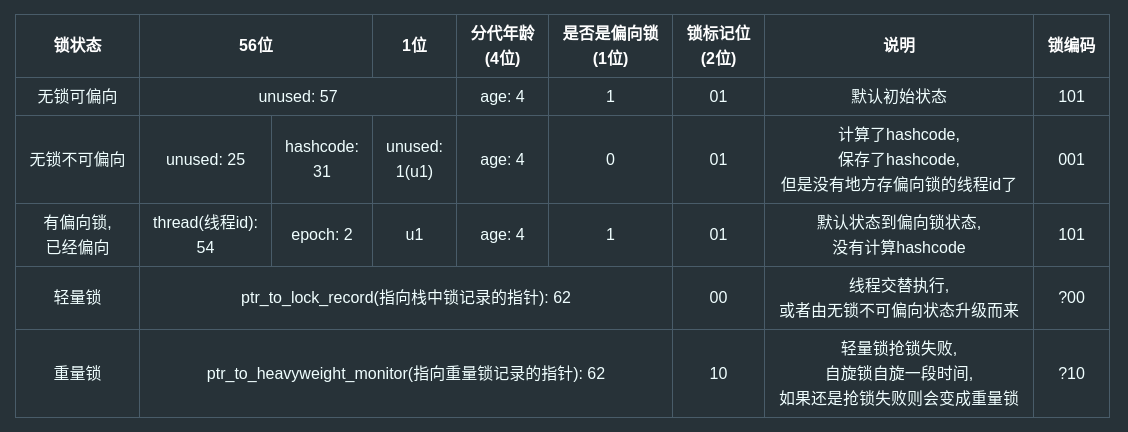
hashcode 默认存储在对象的对象头,但是 ⬇
⚡注意
-
hashcode 采用延迟加载的方式生成。只有调用 hashCode() 方法时,才会写入对象头。若一个类的 hashCode() 方法被重写,对象头中将不存储 hashcode 信息。
-
当该对象的锁状态不是默认状态时,对象的 hashcode 不存储在对象头
当是轻量级锁/重量级锁时,JVM 会将对象的 Mark Word 复制一份到栈帧的 Lock Record 中。等线程释放该对象时,再重新复制给对象。
-
如果一个对象头中存在 hashcode,则无法使用偏向锁。
综合上面两条,即:如果在锁对象加锁前计算了 hashCode ,且 hashCode 方法没有被重写,那么会把 hashCode 存储到 Mark Word 中,加锁时因为无法存放线程 id (偏向锁)或锁记录地址(轻量级锁),不会使用偏向锁
但是会使用轻量级锁。(如上面所说,把 Mark Word 复制到栈帧的 Lock Record 中)
⚡问题
-
hashCode 既然可以生成为什么要放在对象头里?
因为当一个对象的 hashCode() 方法未被重写时,调用这个方法可能会返回一个由随机数算法生成的值。因为一个对象的 hashCode 不可变,所以需要存到对象头中。当再次调用该方法时,会直接返回对象头中的 hashCode,而如果不存储这个 hashCode,同一对象每次调用 hashCode 方法得到的值就都会不相同。
⚡String 实现 hashCode 方法
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}可以看出,相同的字符串调用hashCode()方法,得到的值是一样的,与内存地址、进程、机器无关。代码似乎很简单,但是一定要归纳出来他的实现过程。
hash = val[0]*31{n-1}+val[1]*31{n-2}+…+val[n-1]
注:n为字符串长度。
如果字符串相等,hashcode 必然一样;如果 hashcode 一样,字符串不一定相等,因为计算时可能发生溢出。
-
为什么计算时选择31?
-
31是个奇质数,不大不小,一般质数非常适合hash计算,偶数相当于移位运算,容易溢出,数据信息丢失。如果太小,则产生的哈希值区间小;太大则容易溢出,数据信息丢失。
-
31 * i == (i << 5) - i 。非常易于维护,将移位代替乘除,会有性能的提升,并且JVM执行时能够自动优化成这个样子。
-
通过实验计算,选用31后出现hash冲的概率相比于其他数字要小
-
本博客所有文章除特别声明外,均采用 知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议 。转载请注明出处!