并发知识 -- CPU 硬件架构
本文最后更新于:5 天前
⚡CPU 硬件架构是什么样的
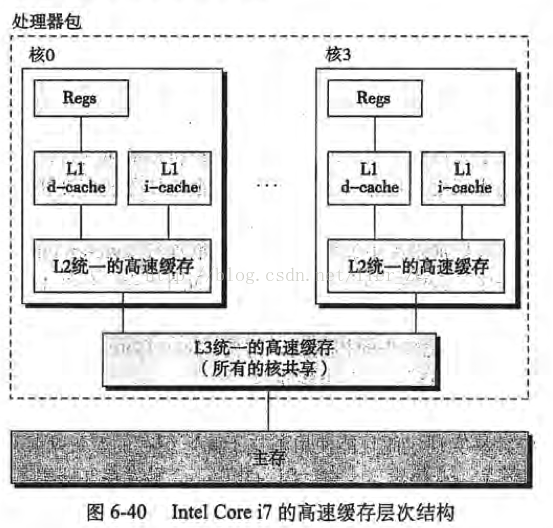
CPU、Cache 以及内存间的简要交互过程:
CPU 读取数据时,首先从寄存器中查找,如果没有找到,则会到 L1 Cache 中查找,如果 L1 Cache 中没有,那么会到 L2 Cache 中查找,L3 Cache 同理,如果 CPU 中没有找到,那么才会到主存中查找。
而写入的时候,大部分 CPU 在写入数据时也会先写 Cache。其原因在于:
-
一方面是因为新存数据很可能会被再次使用,新写数据先写 Cache 能提高缓存命中率;
-
另一方面 CPU 写 Cache 速度更快,从而写完之后 CPU 可以去干别的事情,能提高性能。
CPU 写数据如果 Cache 命中了,则为了保持 Cache 和主存一致有两种策略。
-
如果 CPU 写 Cache 每次都要更新主存,则称为
Write-Through,因为每次写 Cache 都伴随主存更新所以性能差,实际使用的也少; -
写 Cache 之后并不立即写主存而是等待一段时间能积累一些改动后再更新主存的策略称为
Write-Back,性能更好但为了保证写入的数据不丢使机制更加复杂。采用 Write Back 方式被修改的内存再从 Cache 移出(比如 Cache 不够需要腾点空间)时,如果被修改的 Cache Line 还未写入主存需要在被移出 Cache 时更新主存,为了能分辨出哪些 Cache 是被修改过哪些没有,又需要增加一个新的标志位在 Cache Line 中去标识。
CPU 写数据如果 Cache 未命中,则只能直接去更新主存。但更新完主存后又有两个选择,将刚修改的数据存入 Cache 还是不存。每次直接修改完主存都将主存被修改数据所在 Cache Line 存入 Cache 叫做 Write-Allocate。需要注意的是 Cache 存取的最小单位是 Cache Line。即使 CPU 只写一个字节,也需要将被修改字节所在附近 Cache Line 大小的一块内存完整的读入 Cache。如果 CPU 写主存的数据超过一个 Cache Line 大小,则不用再读主存原来内容,直接将新修改数据写入 Cache。相当于完全覆盖主存之前的数据。
L1 Cache 中:
-
d-cache 缓存程序数据
-
i-cache 缓存指令数据(只读)
L2、L3 Cache 不区分指令和程序数据,称为统一缓存
⚡CPU 具体是如何查找的
一个 Cache 由多个块(Cache Line)构成,查找的目标地址必须经过某种映射函数把主内存的地址定位到 Cache Line 中,这里有几种方案:
⚡直接映射
一个内存地址每次映射到固定的 Cache Line
读 Cache 时对内存地址进行哈希(通常是按照 Cache Line 数量取模,即在二进制地址中取中间位)来定位 Cache Line,写 Cache 时如果有冲突则丢掉老的数据。
缺点是内存地址大于 Cache Line 的范围,所以会有多个不同的内存地址映射到相同的 Cache 导致 Cache 淘汰换出频繁,可能不同的进程需要频繁的从主存中读取数据 Cache Line。
⚡全相联映射
内存地址可被的映射到任意的 Cache Line,读 Cache 时遍历整个 Cache Line 的地址,写 Cache 时,可以按照 LFU 或者 LRU 来淘汰旧的 Cache
优点是灵活,Cache 利用率高,冲突概率低,
缺点是设计和实现比较复杂,只适合小容量的 Cache 使用
⚡组相联映射
是上面两种办法的折中,将若干 Cache Line 分为 5个组,将目标地址分为t(标记位),s(组索引),b(块偏移)三个部分。组间直接映射,组内全相联。
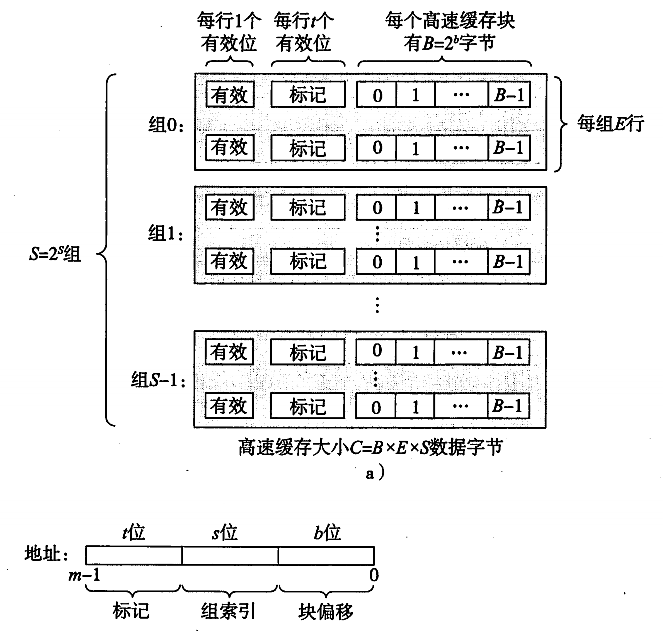
B = 2^b
S = 2^s
现在来解释一下各个参数的意义:
一个 cache 被分为 S 个组,每个组有 E 个 Cache Line,而一个 Cache Line 中,有 B 个存储单元,现代处理器中,这个存储单元一般是以字节(通常8个位)为单位的,也是最小的寻址单元。因此,在一个内存地址中,中间的 s 位决定了该单元被映射到哪一组,而最低的 b 位决定了该单元在 Cache Line 中的偏移量。valid 通常是一位,代表该 Cache Line 是否是有效的(当该 Cache Line 不存在内存映射时,当然是无效的)。tag就是内存地址的高t位,因为可能会有多个内存地址映射到同一个 Cache Line 中,所以该位是用来校验该 Cache Line 是否是CPU要访问的内存单元。
当 tag 和 valid 校验成功时,我们称为 cache命中,这时只要将 cache 中的单元取出,放入CPU寄存器中即可。
当 tag 或 valid 校验失败的时候,就说明要访问的内存单元(也可能是连续的一些单元,如 int 占4个字节,double 占8个字节)并不在cache中,这时就需要去内存中取了,这就是 cache 不命中的情况(cache miss)。当不命中的情况发生时,系统就会从内存中取得该单元,将其装入 cache 中,与此同时也放入 CPU 寄存器中,等待下一步处理。
当 E=1 时, 每组只有一个 Cache Line。那么相隔 2^(s+b) 个单元的2个内存单元,会被映射到同一个 Cache Line 中。
当 1<E<C/B 时,每组有 E 个 Cache Line,不同的地址,只要中间 s 位相同,那么就会被映射到同一组中,同一组中被映射到哪个 Cache Line 中是依赖于替换算法的。
当 E=C/B,S=1 时,每个内存单元都能映射到任意的 Cache Line。带有这样cache的处理器几乎没有,因为这种映射机制需要昂贵复杂的硬件来支持。
⚡CPU 为什么这么设计
在 CPU 工作时直接使用寄存器中的数据,因为寄存器存在 CPU 的内部而且访问速度在内存设备中最快。
但是由于寄存器小,不能存放大量数据,且造价昂贵。所以数据一般存放在内存中,但是内存的访问速度太慢,导致CPU在处理指令时往往花费很多时间在等待内存做准备工作,所以在寄存器和内存之间又加入了缓存,缓存比较小,但访问速度比主内存快得多。
如果 CPU 总是访问内存中的同一址地的数据,此时缓存就可以把从内存提取的数据暂时保存起来,如果寄存器要取内存中同一位置的数据,直接从缓存中提取,无需直接从内存取。
需要注意的是,寄存器并不每次数据都可以从缓存中取得数据,万一不是同一个内存地址中的数据,那寄存器还必须直接绕过缓存从内存中取数据。所以并不每次都得到缓存中取数据,这种现象有个专业的名称叫做缓存的命中率,从缓存中取就命中,不从缓存中取从内存中取,就没命中,可见缓存命中率的高低也会影响CPU执行性能。
总而言之当一个 CPU 需要访问主存时,会先根据时间/空间局部性原理多读取一部分数据到CPU缓存(当然如果CPU缓存中存在需要的数据就会直接从缓存获取),进而在读取CPU缓存到寄存器,当CPU需要写数据到主存时,同样会先刷新寄存器中的数据到CPU缓存,然后再把数据刷新到主内存中。
本博客所有文章除特别声明外,均采用 知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议 。转载请注明出处!