并发知识 -- CPU 缓存一致性
本文最后更新于:5 天前
CPU 的多级高速缓存引入了一个新的问题:缓存一致性(Cache Coherence)。在多核 CPU 系统中,每个 CPU 都有自己的高速缓存,而它们又公用一块主内存(Main Memory)。当多个 CPU 的运算任务都涉及同一块主内存区域时,将可能导致各自的缓存不一致。如果真发生这种情况,那同步回到主内存时以谁的缓存数据为准呢?
⚡总线加锁
通过在总线上加 LOCK# 锁的形式可以解决缓存不一致的问题。
因为CPU和其他部件进行通信都是通过总线来进行的,如果对总线加LOCK#锁的话,也就是说阻塞了其他CPU对其他部件访问(如内存),从而使得只能有一个CPU能使用这个变量的内存。
但是这种方式会有一个问题,由于在锁住总线期间,其他 CPU 无法访问内存,导致效率低下。
由于总线加 Lock 锁的方式效率低下,后来便出现了缓存一致性协议。最出名的就是 Intel 的 MESI 协议。
⚡缓存一致协议(MESI 协议为例)
其主要思想是:
当 CPU 写数据时,如果发现操作的变量是共享变量,即在其他 CPU 中也存在该变量的副本,会发出信号通知其他 CPU 将该变量的缓存行置为无效状态,因此当其他 CPU 需要读取这个变量时,发现自己缓存中缓存该变量的缓存行是无效的,那么它就会从内存重新读取。
定义了 Cache Life 的四种状态:
| 状态 | 描述 |
|---|---|
| M(Modified) | 这行数据有效,数据被修改了,和内存中的数据不一致,当前数据只存在于本Cache中。 |
| E(Exclusive) | 这行数据有效,数据和内存中的数据一致,数据只存在于本Cache中。 |
| S(Shared) | 这行数据有效,数据和内存中的数据一致,数据存在于很多Cache中。 |
| I(Invalid) | 这行数据无效。 |
-
一个处于M状态的缓存行,必须时刻监听所有试图读取该缓存行对应的主存地址的操作,如果监听到,则必须在此操作执行前把其缓存行中的数据写回CPU,将自己的状态变成s。
-
一个处于S状态的缓存行,必须时刻监听使该缓存行无效或者独享该缓存行的请求,如果监听到,则必须把其缓存行状态设置为I。
-
一个处于E状态的缓存行,必须时刻监听其他试图读取该缓存行对应的主存地址的操作,如果监听到读操作,则必须把其缓存行状态设置为S。
除了状态之外,CPU还需要一些消息机制:
-
Read: CPU发起读取数据请求,请求中包含需要读取的数据地址。
-
Read Response: 作为Read消息的响应,该消息可能是内存响应的,也可能是某CPU响应的(比如该地址在某CPU Cache Line中为Modified状态,该CPU必须返回该地址的最新数据)。
-
Invalidate: 该消息包含需要失效的地址,所有的其它CPU需要将对应Cache置为Invalid状态
-
Invalidate Ack: 收到Invalidate消息的CPU在将对应Cache置为Invalid后,返回Invalid Ack
-
Read Invalidate: 相当于Read消息+Invalidate消息,即取得数据并且独占它,将收到一个Read Response和所有其它CPU的Invalid Ack
-
Writeback: 写回消息,即将状态为Modified的行写回到内存,通常在该行将被替换时使用。现代CPU Cache基本都采用”写回(Write Back)”而非”直写(Write Through)”的方式。
MESI 还有进一步优化的空间 ⬇
⚡优化
⚡Store Buffer
写入 Cache 时,如果不是 M 或者 E 状态,需要发送一个 Invalidate 消息给其他 CPU,然后等待其他 CPU 的 Invalidate Ack 回应之后,才会进行写入,但是这样就有了等待的时间,影响了性能。
有一种解决办法就是引入 Store Buffer:
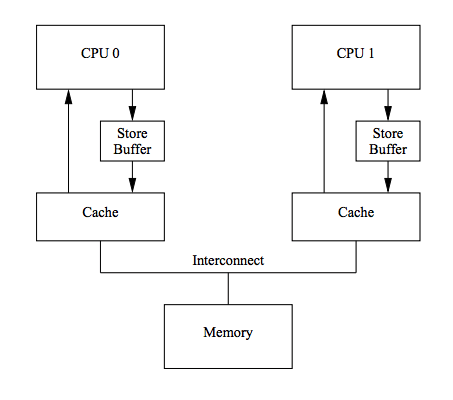
CPU 不再需要等待其他 CPU 的响应,只需要把修改内容装入 store buffer,然后继续执行,当状态改变之后,再把数据从 store buffer 写入 Cache Line 中
但是这也产生了新的问题
初始状态下,假设a,b值都为0,并且a存在CPU1的Cache Line中(Shared状态),可能出现如下操作序列:
-
CPU0 要写入A,发出Read Invalidate消息,并将a=1写入Store Buffer
-
CPU1 收到Read Invalidate,返回Read Response(包含a=0的Cache Line)和Invalidate Ack
-
CPU0 收到Read Response,更新Cache Line(a=0)
-
CPU0 开始执行 b = a + 1,从Cache Line中加载a,得到a=0
-
CPU0 将Store Buffer中的a=1应用到Cache Line
-
CPU0 得到 b=0+1,断言失败
导致这个问题的根本原因是我们有两个a值,一个在cacheline中,一个在store buffer中。
这个出错的例子之所以发生是因为它违背了一个基本的原则,即每个CPU按照其视角来观察自己的行为的时候必须是符合 program order 的。一旦违背这个原则,会导致一些非常不直观的软件行为,对软件工程师而言就是灾难。
⚡Store Forwarding
由于单纯的 store buffer 的问题,硬件工程师在 Store Buffer 的基础上,又实现了"Store Forwarding"技术: CPU 可以直接从 Store Buffer 中加载数据,即支持将CPU 存入 Store Buffer 的数据传递(forwarding)给后续的加载操作,而不经由Cache。
所以,对于上面的问题,使用 Store Forwarding 可以从 store buffer 中获取到 a 为 1 而不是 0,程序正确
看看下面的对比:
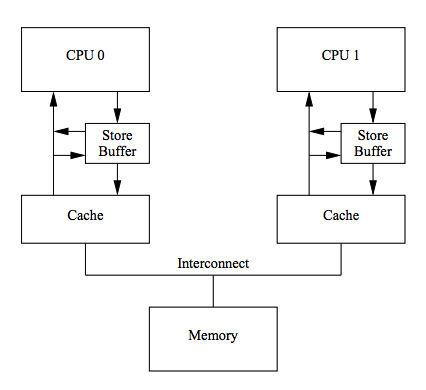
虽然 store forwarding 解决了同一个CPU读写数据的问题,再来看看并发程序:
// CPU0 执行,没有缓存 a
void foo() {
a = 1;
b = 1;
}
// CPU1 执行,没有缓存 b
void bar() {
while (b == 0) continue;
assert(a == 1)
}假设初始状态下,a=0,b=0,a存在于CPU1的Cache中,b存在于CPU0的Cache中,均为Exclusive状态,CPU0执行foo函数,CPU1执行bar函数,上面代码的预期显然为断言为真。那么来看下执行序列:
-
CPU1执行while(b == 0),由于CPU1的Cache中没有b,发出Read b消息
-
CPU0执行a = 1,由于CPU0的Cache中没有a,因此它将a(当前值1)写入到Store Buffer并发出Read Invalidate a消息
-
CPU0执行b = 1,由于b已经存在在Cache中(Exclusive),因此可直接执行写入
-
CPU0收到Read b消息,将Cache中的b(当前值1)返回给CPU1,将b写回到内存,并将Cache Line状态改为Shared
-
CPU1收到包含b的Cache Line,结束while (b == 0)循环
-
CPU1执行assert(a == 1),由于此时CPU1 Cache Line中的a仍然为0并且有效(Exclusive),断言失败
-
CPU1收到Read Invalidate a消息,返回包含a的Cache Line,并将本地包含a的Cache Line置为Invalid(已经晚了)
-
CPU0收到CPU1传过来的Cache Line,然后将Store Buffer中的a(当前值1)刷新到Cache Line
上面的问题简单来说就是,当 CPU0 执行 foo 时,由于没有缓存 a,但是缓存了 b,所以对于 a 来说只能先写到 store buffer 里面,但是 b 来说可以直接写入,并且此时 CPU 1 来说,b 的值已经可以看到被修改,然后跳出循环,执行后面的断言 a==1,但是此时 a 在这个 CPU1 的缓存还没有来得及失效,所以就直接使用了它自己的缓存中的 a = 0 的值,导致断言失败。
而问题发生的原因是:对于 CPU 来说,它不知道 a 和 b 之间的数据依赖,CPU0 对 a 是写入 store buffer,而对于 b 则是写入 cache
⚡内存屏障
为了解决这个问题,我们可以在 foo 中 a = 1 和 b = 1 之间加上内存屏障。
void foo() {
a = 1;
smp_mb()
b = 1;
}
void bar() {
while (b == 0) continue;
assert(a == 1)
}当遇到 smp_mb() 时,会先刷新屏障前的 store buffer, 然后执行屏障后 cache 的写入。
这里刷新 store buffer 有两种方式,第一种是等待相关的 Read Response 返回,再写入 cache,但是这样和没有使用 store buffer 一样,有等待时间的浪费;第二种方式则是将屏障前的所有 store buffer 都打上标记,然后 CPU 后续所有的修改都写入到 store buffer里面(不管 cache 中是否存在),直到屏障前的数据(所有被打上标记的数据)都写入到 Cache Line 中之后,才会按照以前的,如果缓存中存在且状态为 E 则直接写入缓存
-
CPU1执行while(b == 0),由于CPU1的Cache中没有b,发出Read b消息
-
CPU0执行a = 1,由于CPU0的Cache中没有a,因此它将a(当前值1)写入到Store Buffer并发出Read Invalidate a消息
-
CPU0看到smp_mb()内存屏障,它会标记当前Store Buffer中的所有条目(即a = 1被标记)
-
CPU0执行b = 1,尽管b已经存在在Cache中(Exclusive),但是由于Store Buffer中还存在被标记的条目,因此b不能直接写入,只能先写入Store Buffer中
-
CPU0收到Read b消息,将Cache中的b(当前值0)返回给CPU1,将b写回到内存,并将Cache Line状态改为Shared
-
CPU1收到包含b的Cache Line,继续while (b == 0)循环
-
CPU1收到Read Invalidate a消息,返回包含a的Cache Line,并将本地的Cache Line置为Invalid
-
CPU0收到CPU1传过来的包含a的Cache Line,然后将Store Buffer中的a(当前值1)刷新到Cache Line,并且将Cache Line状态置为Modified
-
由于CPU0的Store Buffer中被标记的条目已经全部刷新到Cache,此时CPU0可以尝试将Store Buffer中的b=1刷新到Cache,但是由于包含B的Cache Line已经不是Exclusive而是Shared,因此需要先发Invalid b消息
-
CPU1收到Invalid b消息,将包含b的Cache Line置为Invalid,返回Invalid Ack
-
CPU1继续执行while(b == 0),此时b已经不在Cache中,因此发出Read消息
-
CPU0收到Invalid Ack,将Store Buffer中的b=1写入Cache
-
CPU0收到Read消息,返回包含b新值的Cache Line
-
CPU1收到包含b的Cache Line,可以继续执行while(b == 0),终止循环
-
CPU1执行assert(a == 1),此时a不在其Cache中,因此发出Read消息
-
CPU0收到Read消息,返回包含a新值的Cache Line
-
CPU1收到包含a的Cache Line,断言为真
可能看到这里的流程会有疑惑,如果 Read Invalid 一直没有返回,也就是 store buffer 里面的 a 和 b 的值一直都没来得及刷新到 Cache Line,那么 bar 函数也一直无法向后运行,这和没有 store buffer 不是一样了吗?
其实不然,因为这里另一个 CPU 执行的 bar 函数只是正好受限于共享变量 b,如果其他函数或者程序没有因为这个 b 的值而不能运行,而是一直向下执行,那么这个实际上是有时间上面的节省的。
⚡Invalid Queue
现在还有一个问题没有考虑到:Store Buffer 的大小是有限的,所有写入操作的 Cache Missing 都会使用 Store Buffer,特别是出现内存屏障时,后续的所有写入操作(不管是否Cache Miss)都会存储在在 Store Buffer 中,直到 Store Buffer 中屏障前的条目处理完。
因此 Store Buffer 很容易会满,当 Store Buffer 满了之后,CPU 还是会卡在等对应的 Invalid Ack 以处理 Store Buffer 中的条目。
问题的原因在于 Invalid Ack,Invalid Ack 耗时的主要原因是 CPU 要先将对应的Cache Line 置为 Invalid 后再返回 Invalid Ack,一个很忙的 CPU 可能会导致其它CPU 都在等它回 Invalid Ack。
其解决思路就是异步: CPU不必要处理了Cache Line之后才回Invalid Ack,而是可以先将Invalid消息放到某个请求队列Invalid Queue,然后就返回Invalid Ack。CPU可以后续再处理Invalid Queue中的消息,大幅度降低Invalid Ack响应时间。
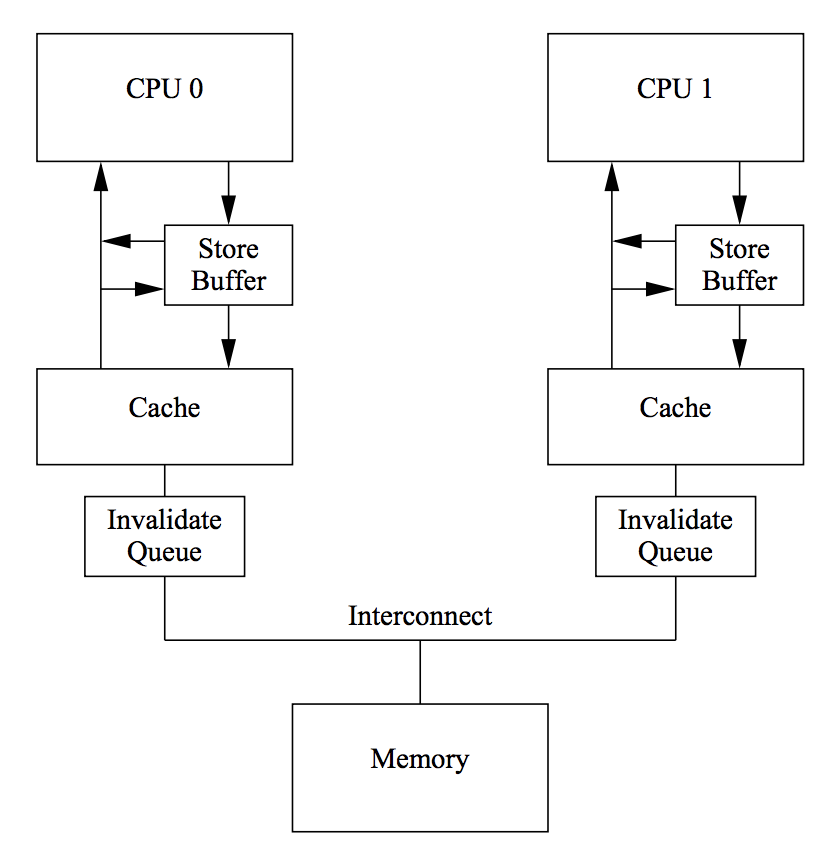
Invalid Queue有两个问题要考虑
-
CPU在处理任何Cache Line 的 MSEI 状态前,都必须先看 Invalid Queue 中是否有该 Cache Line 的 Invalid 消息没有处理。这一点在CPU数据竞争不是很激烈时是可以接受的。
此前的内存屏障实际上是一个写屏障,其实还有读屏障
1.另一个要考虑的问题是它也增加了破坏内存一致性的可能,即可能破坏我们之前提到的内存屏障:
上面加入了内存屏障的代码,CPU 也有可能按照如下的情况执行:
-
CPU0执行a = 1,由于其有包含a的Cache Line,将a写入Store Buffer,并发出Invalidate a消息
-
CPU1执行while(b == 0),它没有b的Cache,发出Read b消息
-
CPU1 收到 CPU0 的 Invalidate a消息,将其放入 Invalidate Queue,返回Invalidate Ack
-
CPU0 收到 Invalidate Ack,将 Store Buffer 中的 a=1 刷新到 Cache Line,标记为 Modified
-
CPU0 看到 smp_mb() 内存屏障,但是由于其 Store Buffer 为空,因此它可以直接跳过该语句
-
CPU0 执行 b = 1,由于其 Cache 独占 b,因此直接执行写入,Cache Line 标记为 Modified,
-
CPU0 收到 CPU1发 的 Read b 消息,将包含 b 的 Cache Line 写回内存并返回该 Cache Line,本地的 Cache Line 标记为 Shared
-
CPU1 收到包含b(当前值1)的Cache Line,结束while循环
-
CPU1执行 assert(a == 1),由于其本地有包含a旧值的Cache Line,读到a初始值0,断言失败
-
CPU1这时才处理Invalid Queue中的消息,将包含a旧值的Cache Line置为Invalid
出现问题的地方就是在于 CPU1 读取 a 的 Cache Line 时,没有先去处理 Invalid Queue 中的 Invalid 操作。其本质问题是由于增加了 Invalid Queue 使得打破了内存屏障(写屏障)的语义
解决办法还是内存屏障(读屏障):
我们可以通过内存屏障让 CPU 标记当前 Invalid Queue 中所有的条目,所有的后续加载操作必须先等 Invalid Queue 中标记的条目处理完成再执行。
具体步骤是其实不是 CPU 遇到读屏障就立即去处理 Invalid Queue,而是标记 Invalidate Queue 上的 Cache Line,之后继续执行别的指令,直到看到下一个 Load 操作要从 Cache Line 里读数据了,CPU 才会等待 Invalidate Queue 内所有刚才被标记的 Cache Line 都处理完才继续执行下一个 Load。
因此我们可以在 while 和 assert 之间插入 smp_mb()。这样 CPU1 在看到 smp_mb() 后,会先标记 Invalidate Queue 所有的数据,然后继续读取 a 的值,但是读取的时候发现 Invalid Queue 还有标记的数据,于是等待标记的数据处理完,然后发现 a 的状态为 I,重新从 CPU0 获取,得到 a 的值为1,断言成立。
void foo() {
a = 1;
smp_mb()
b = 1;
}
void bar() {
while (b == 0) continue;
smp_mb()
assert(a == 1)
}⚡CPU 为了保证缓存一致性而产生的 False Sharing 问题
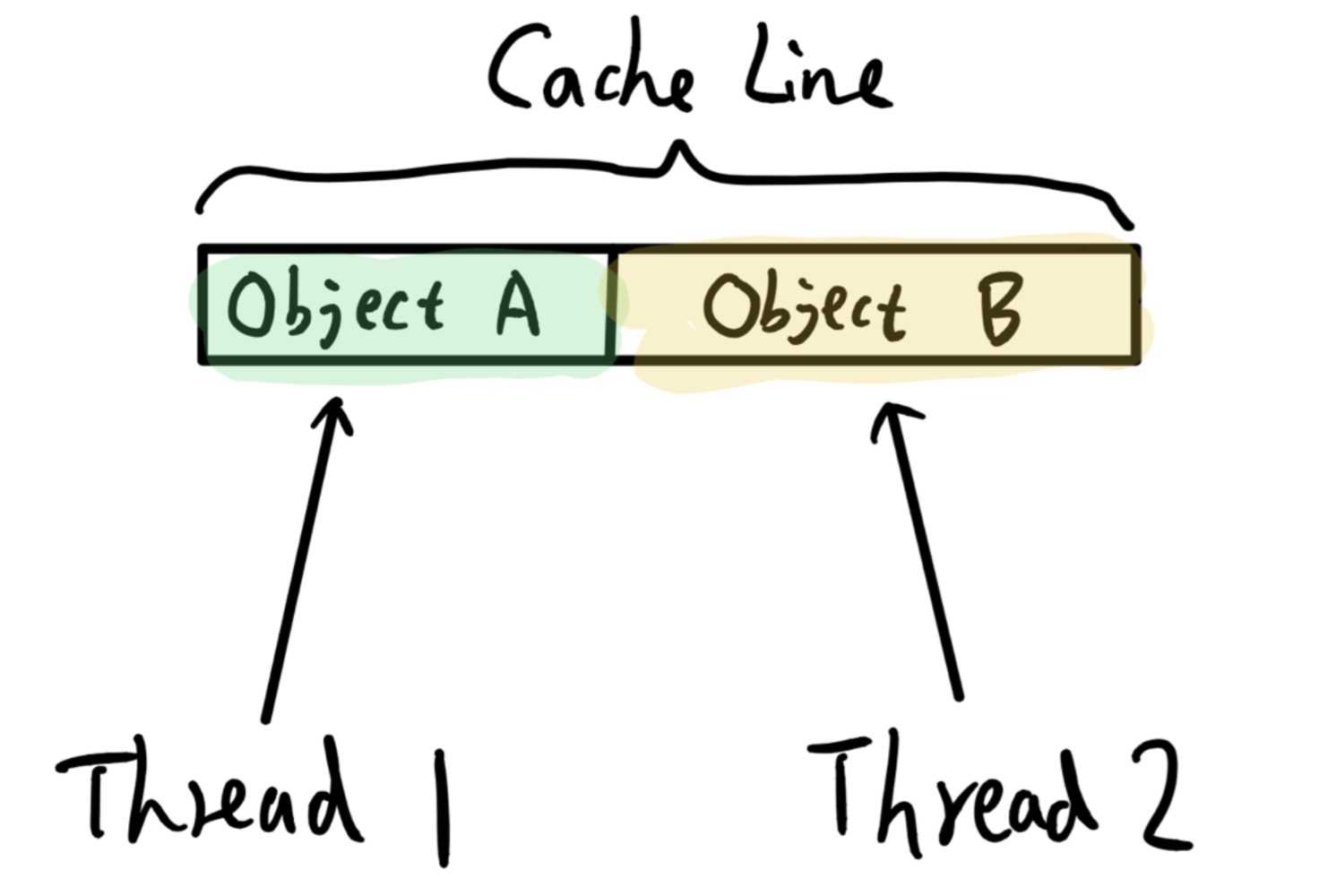
A、B 两个对象在内存上被连续的创建在一起,假若这两个对象都很小,小于一个 Cache Line 大小,那他们可能会共用同一个 Cache Line。如果再有两个线程 Thread 1 和 Thread 2 会去操作这两个对象,我们从代码角度保证 Thread 1 只会操作 A,而 Thread2 只会操作 B。那按道理这两个 Thread 访问 A B 不该有相互影响,都能并行操作。但现在因为它俩刚好在同一个 Cache Line 内,就会出现 A B 对象所在 Cache Line 在两个 CPU 上来回搬迁的问题。
比如 Thread 1 要修改对象 A,那 Thread 1 所在 CPU 1 会先获取 A 所在 Cache Line 的 Exclusive 权限,会发送 Invalidate 给其它 CPU 让其它 CPU 设置该 Cache Line 为无效。之后 Thread 2 要修改对象 B,Thread 2 所在 CPU 2 又会尝试获取 B 所在 Cache Line 的 Exclusive 权限,会发 Invalidate 给其它 CPU,包括 CPU 1。CPU 1 要是已经写完了 A,那就要把数据刷写内存,之后设置 Cache Line 无效并响应 Invalidate。没写完就得等待 CPU 1 写完 A 后再处理 Cache Line 的 Invalidate 问题。之后 CPU 2 再去操作 Cache Line 更新 B 对象。再后来 Thread 1 要去更新 A 对象的话又要去把 A B 所在 Cache Line 在 CPU 2 上设置无效。也就是说这块 Cache Line 失去了 Cache 功能,会在两个 CPU 上来回搬迁,会经常性的执行刷写内存,读取内存操作,导致两个本来看上去没有关系的操作实际上有相互干扰。
False Sharing 问题其实不会很常见,不过 TLAB 和 PLAB 机制可能会增大它出现的几率。
一般 TLAB 大于 Cache Line 所以不会引起 False Sharing 问题。JVM 上容易引起 False Sharing 的情况是:一个线程连续分配了两个对象,这两个对象后来被分配给不同的线程,并且被它们频繁更新,这两个对象在两个不同线程上就容易出现 False Sharing 问题,即使经历数轮 GC,它俩可能在内存上还是可能在一起,所以说 TLAB 和 PLAB 会增大 False Sharing 出现的概率。
⚡内存屏障的种类
看似这个内存屏障就是改变了 Invalid Queue 的处理方式而已,其实第一个写屏障只是关心 Store Buffer 中有没有标记的值,而这里的读屏障其实只关心 Invalid Queue 中有没有标记的值,这其实也是大多数 CPU 划分的内存屏障的类型:读屏障(Read Memory Barrier)和写屏障(Write Memory Barrier):
-
读屏障: 任何读屏障前的读操作都会先于读屏障后的读操作完成
对于读屏障,它只是约束执行 CPU 上的 load 操作的顺序,具体的效果就是 CPU 一定是完成读屏障之前的 load 操作之后,才开始执行读屏障之后的 load 操作。读屏障像一道栅栏,严格区分了之前和之后的 load 操作。
-
写屏障: 任何写屏障前的写操作都会先于写屏障后的写操作完成
和读屏障类似,严格区分写屏障之前和之后的 store 操作
-
全屏障: 同时包含读屏障和写屏障的作用
在前面的例子中,foo 函数只需要写屏障,bar 函数需要读屏障。实际的 CPU 架构中,可能提供多种内存屏障,比如可能分为四种:
-
LoadLoad: 相当于前面说的读屏障
-
LoadStore: 任何该屏障前的读操作都会先于该屏障后的写操作完成
-
StoreLoad: 任何该屏障前的写操作都会先于该屏障后的读操作完成
-
StoreStore: 相当于前面说的写屏障
其实现原理类似,都是基于 Store Buffer 和 Invalidate Queue
⚡问题
-
为什么修改值有 Read Invalid,直接赋值不就好了吗
CPU0 对a 进行写入操作,虽然 CPU0 中没有 a 的缓存,但是也按理说无需知道 a 的初值,直接赋值就好了,为什么还要发送"Read"消息呢?
因为一个 Cache Line 中不止是包含 a 的数据,例如cache line有256字节而a可能只有4字节,写a不能使同数据块的其它值受影响。
本博客所有文章除特别声明外,均采用 知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议 。转载请注明出处!