ORM 解决业务需求带来的 N+1 问题
本文最后更新于:12 天前
⚡什么是 1+N 问题
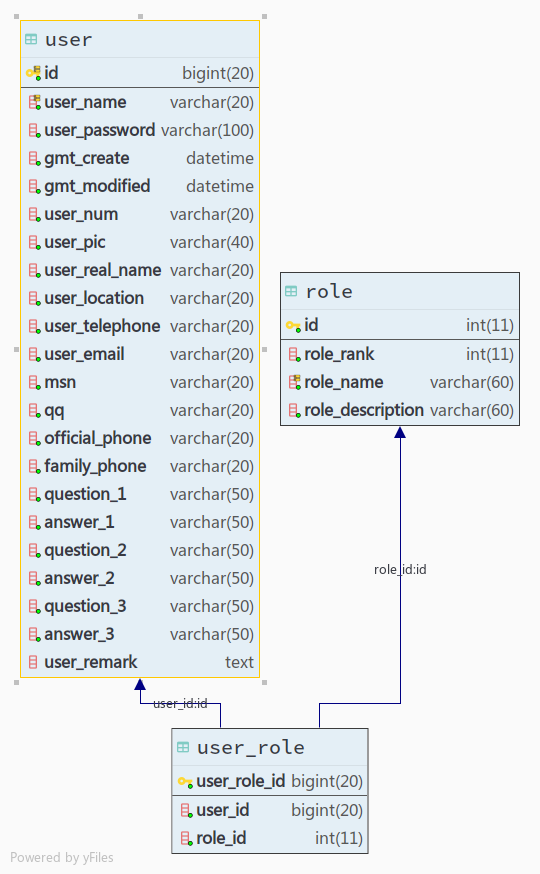
如图,user 表为用户的基本信息表,role 则是系统内所有角色信息,而用户可能会有多种角色,根据数据库范式,user 和 role 通过 user_role 表相关联,代表一个用户可以有多个角色,一个角色也可以有多个用户。
这样建表,虽然遵循了范式,提供了系统的扩展性,但是有一个问题,当我们想要去查找一个用户所有的角色信息时,需要先从 user_role 表里面找到这个用户的所有角色id(role_id),然后再根据 role_id 去 role 表里面找到相关的角色信息。
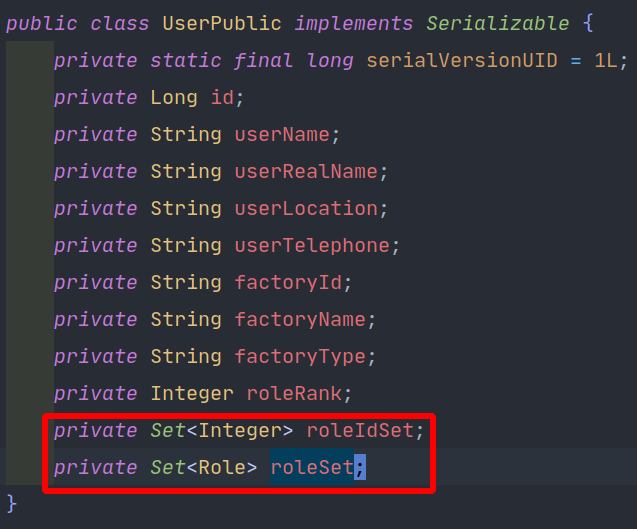
如图,最后两个字段的信息需要连接查询才能得到
这样,就产生了 1+N 问题:查找一个用户的角色要先根据 user_id 查找到 N 个 role_id,再对每个 role_id 查找,总共查找了 1+N 次
# 1 次查询
select user.*,role_id
from user
left join user_role on id = user_id
where user_id = 1;
# N 层循环(Java 代码级别而非数据库级别)
for(1:N){
select role.* from role where role = var
}⚡如何解决
⚡SQL(连接查询)不推荐
select u.id as id,
user_name,
user_real_name,
user_location,
user_telephone,
role_id,
role_rank,
role_name,
role_description
from user as u left join user_role as ur
on u.id = ur.user_id
left join role as r
on r.id = ur.role_id
where u.id = ?但是,这样还是会有一些瑕疵。

即:前面 user 表的基本信息全部都重复了,而只有后面 role_id 和 role_rank 等信息是不同的,这样只能返回多个部分属性相同的实体集合(collection),对于上面要求的 POJO 还要再进行处理,这个 SQL 和 POJO 并不能对应上,本质上不能代表我们的需求,而且,我们在代码层用 Java 再对返回的 List 或者 Set 进行处理时,又明显会比数据库层慢一些,而且处理也会有些麻烦。
期望的解决方案是可以对 user 表进行分组,得到一行 user 基本信息,然后把 user_id 这个字段变成一个集合,其他的字段例如 user_rank 也同理变成集合,但是,mysql 没有这样的聚集函数或者分组函数。而且,就算有这样的函数,user_id 和 user_rank 处理之后能否对应也是一个问题。
⚡ORM
⚡MyBatis 集合的嵌套 select 查询+懒加载
UserMapper.xml
<resultMap id="UserPublicResultMap" type="com.cloud.farming.entity.model.UserPublic">
<!-- id 和 result 两者之间的唯一不同是,id 元素对应的属性会被标记为对象的标识符,在比较对象实例时使用。 这样可以提高整体的性能,尤其是进行缓存和嵌套结果映射(也就是连接映射)的时候。 -->
<id column="id" property="id"/>
<result column="user_name" property="userName"/>
<result column="user_real_name" property="userRealName"/>
<result column="user_location" property="userLocation"/>
<result column="user_telephone" property="userTelephone"/>
<collection column="id" property="roleIdSet"
javaType="java.util.Set" select="com.cloud.farming.repository.UserRoleMapper.findRoleIdSetByUserId"
ofType="java.lang.Integer" fetchType="lazy"/>
<collection column="id" property="roleSet" ofType="com.cloud.farming.entity.model.Role"
select="com.cloud.farming.repository.UserRoleMapper.findRoleSetByUserId" fetchType="lazy"/>
</resultMap><select id="findUserPublicByUserId" resultMap="UserPublicResultMap">
select id, user_location, user_telephone, user_name, user_real_name
from user
where id = #{userId,jdbcType=BIGINT}
</select>UserRoleMapper.xml
<!-- UserRoleMapper.findRoleIdSetByUserId -->
<!-- 返回值是 Set<Integer> -->
<select id="findRoleIdSetByUserId" resultType="java.lang.Integer">
select role_id
from user_role
where user_id = #{userId,jdbcType=BIGINT}
</select>
<!-- UserRoleMapper.findRoleSetByUserId -->
<!-- 返回值是 Set<Role> -->
<select id="findRoleSetByUserId" resultMap="com.cloud.farming.repository.RoleMapper.BaseResultMap">
select role.id, role_rank, role_name, role_description
from user_role
left join role
on user_role.role_id = role.id
where user_id = #{userId,jdbcType=BIGINT}
</select>上面的 SQL 语句新增的实际上只有一条即,UerMapper 的findUserPublicByUserId,其他 UserRoleMapper 都是之前已有的。
结果:
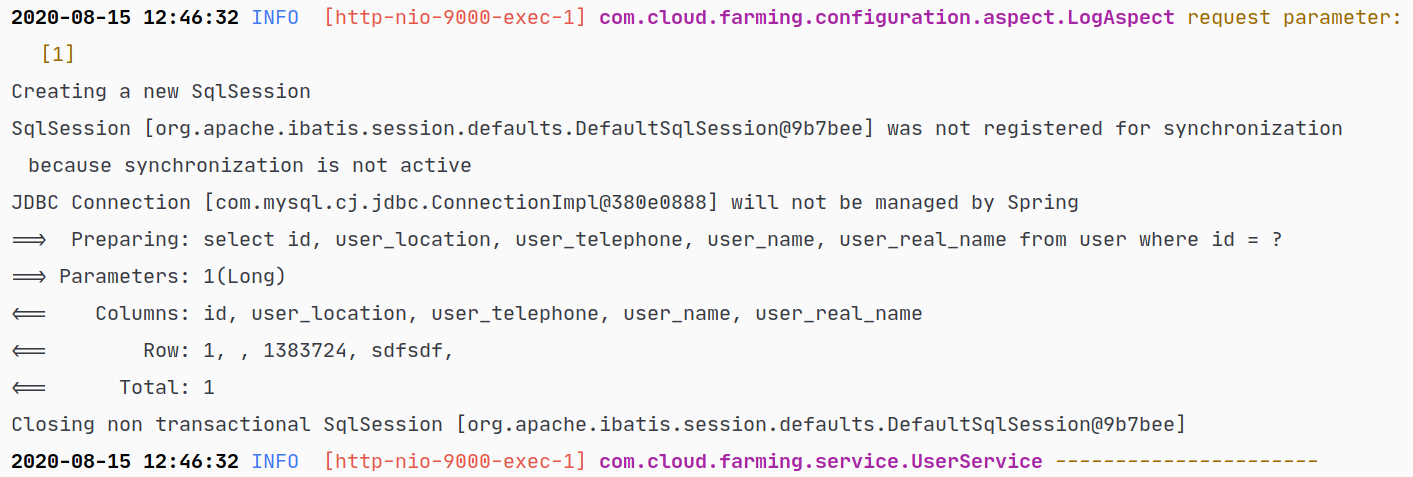
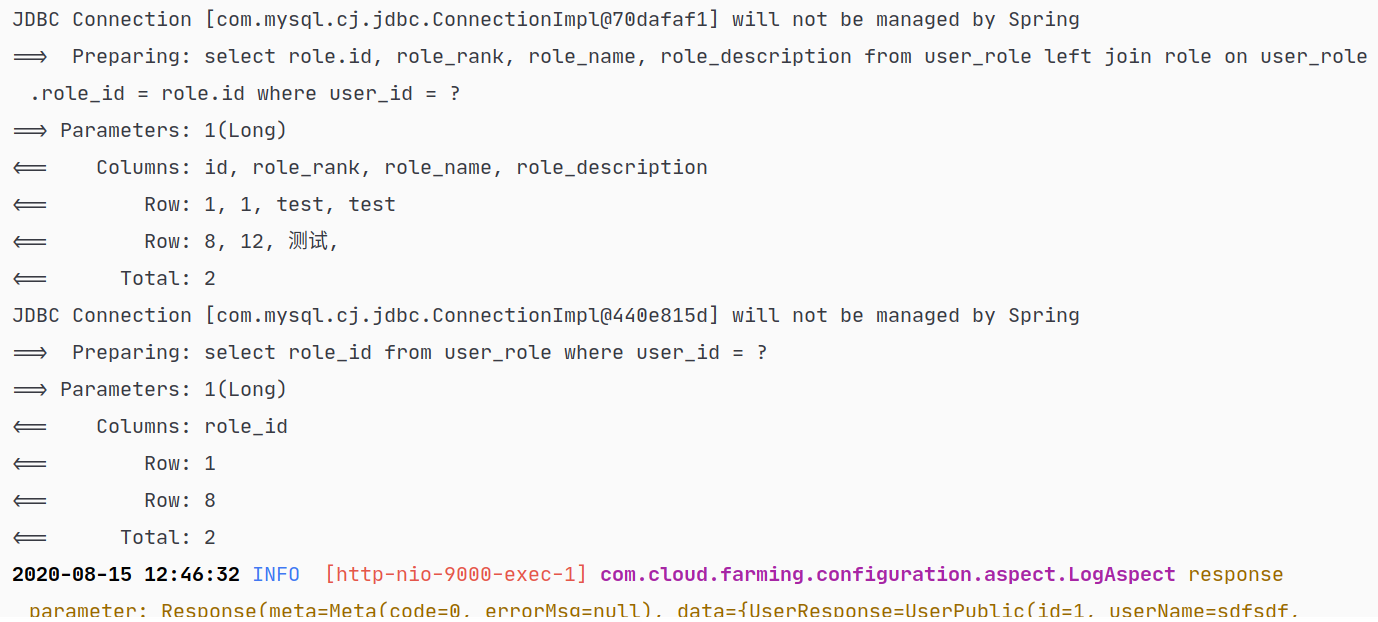
这样,直接调用 UserMapper.xml 的查询语句findUserPublicByUserId时,对于 association 的字段可以由 MyBatis 帮我们执行,不需要我们手动写连接查询,从另一个角度说,如果像上面第一种方法,一条 SQL 语句中连接查询根本无法得到我们想要的格式的数据,使用这个方式也可以很好的解决问题。
但是这样看起来只是将 SQL 复用以及避免了单个语句中的连接查询,应该还是存在 1+N 问题,而且这样感觉将问题反而表现的更加明显了。
一个在某些情况下可用的方案是懒加载。association 标签中的 fetchType = lazy 则是处于性能的考虑,如果我们有时不需要这些信息,没有调用相关字段的 get 方法,那么此时由于懒加载直接不进行 association 的查询,字段返回空,这样可以大幅减少数据库的 IO 操作也就从源头上解决了 1+N 的问题。
当然,这样做的前提是懒加载字段确实不需要才可用。
然而,退一步说,即使没有懒加载,如果二次查询字段使用了 MyBatis 的二级缓存,那么直接命中缓存性能会更高;或者,如果二次查询的字段使用了外键或者索引,这样效率说不定也会比多表连接好一些,可读性,复用性也会更好。
⚡集合的嵌套结果映射
UserMapper.xml
<resultMap id="UserPublicResultMapWithoutN+1" type="com.cloud.farming.entity.model.UserPublic">
<id column="id" property="id"/>
<result column="user_name" property="userName"/>
<result column="user_real_name" property="userRealName"/>
<result column="user_location" property="userLocation"/>
<result column="user_telephone" property="userTelephone"/>
<collection property="roleSet" ofType="com.cloud.farming.entity.model.Role"
resultMap="com.cloud.farming.repository.RoleMapper.RoleResultMap"/>
<!-- resultSet="roles" column="role_id" foreignColumn="user_id"/>-->
<collection property="roleIdSet" ofType="java.lang.Integer" javaType="java.util.Set" column="role_id" >
<id column="role_id" javaType="java.lang.Integer" property="value"/>
</collection>
</resultMap><select id="findUserRolesByUserIdWithoutN" resultMap="UserPublicResultMapWithoutN+1">
select u.id as id,
user_name,
user_real_name,
user_location,
user_telephone,
role_id,
role_rank,
role_name,
role_description
from user as u left join user_role as ur
on u.id = ur.user_id
left join role as r
on r.id = ur.role_id
where u.id = #{userId,jdbcType=BIGINT}
</select>这样直接关联再配合 MyBatis 的缓存 <cache/>,可以将性能调整到极致。
第一次查询数据库:
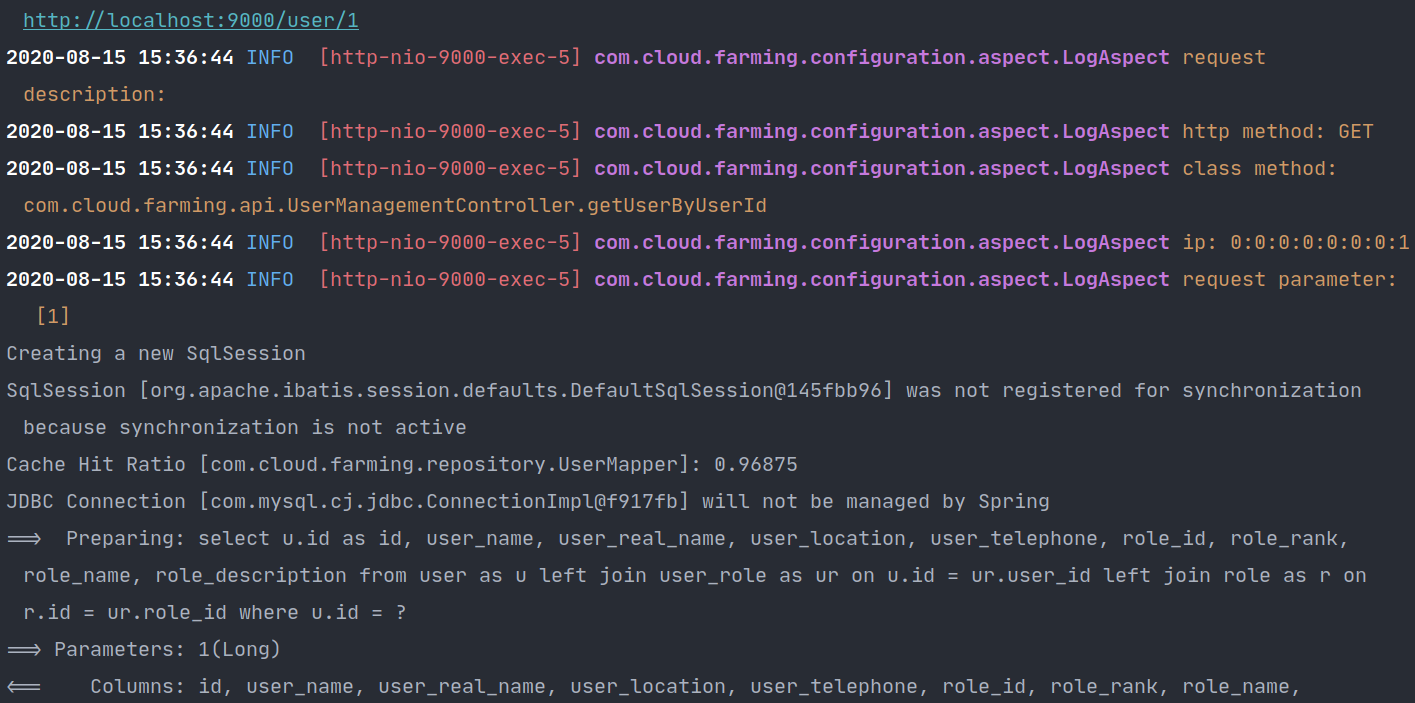
第二次直接命中缓存,没有查询数据库
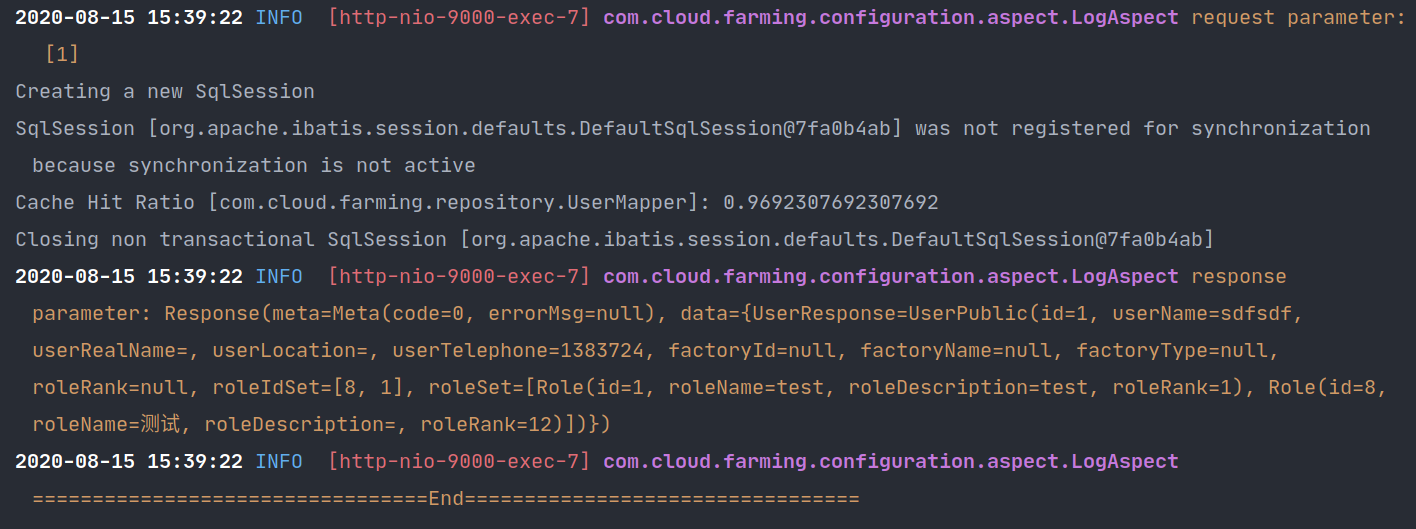
⚡集合的多结果集
官方文档原话:
从版本 3.2.3 开始,MyBatis 提供了另一种解决 N+1 查询问题的方法。
某些数据库允许存储过程返回多个结果集,或一次性执行多个语句,每个语句返回一个结果集。 我们可以利用这个特性,在不使用连接的情况下,只访问数据库一次就能获得相关数据。
存储过程要比单个 SQL 快
虽然存储过程有三个好处:安全,简单,高性能,但是阿里归约中并不推荐,原因是难以调试和扩展,更没有移植性.
然而,这个规约我认为要视情况而定,大部分情况下都没有移植或者扩展的要求。不过每次去写一个存储过程也的确有些麻烦,而且此处我也尝试测试使用过,但是有报错的问题,没有多浪费时间解决,先留做记录,如果后续需要可以尝试使用。